mirror of
https://github.com/dragonflydb/dragonfly.git
synced 2025-05-10 18:05:44 +02:00
docs(dashtable): Fix image URL for expiration (#870)
docs(dashtable): Fix image URL for expiration Replaces the `expiration.svg` image with a working URL. Signed-off-by: Tarun Pothulapati <tarunpothulapati@outlook.com>
This commit is contained in:
parent
d165994b88
commit
e8ca27971c
1 changed files with 6 additions and 5 deletions
|
|
@ -8,7 +8,6 @@ Each selectable database holds a primary dashtable that contains all its entries
|
|||
|
||||

|
||||
|
||||
|
||||
## Redis dictionary
|
||||
|
||||
*“All problems in computer science can be solved by another level of indirection”*
|
||||
|
|
@ -19,7 +18,6 @@ We shamelessly "borrowed" a diagram from [this blogpost](https://codeburst.io/a-
|
|||
Each `RD` is in fact two hash-tables (see `ht` field in the diagram below). The second instance is used for incremental resizes of the dictionary.
|
||||
Each hash-table `dictht` is implemented as a [classic hashtable with separate chaining](https://en.wikipedia.org/wiki/Hash_table#Separate_chaining). `dictEntry` is the link-list entry that wraps each key/value pair inside the table. Each dictEntry has three pointers and takes up 24 bytes of space. The bucket array of `dictht` is resized at powers of two, so usually its utilization is in [50, 100] range.
|
||||
|
||||
|
||||
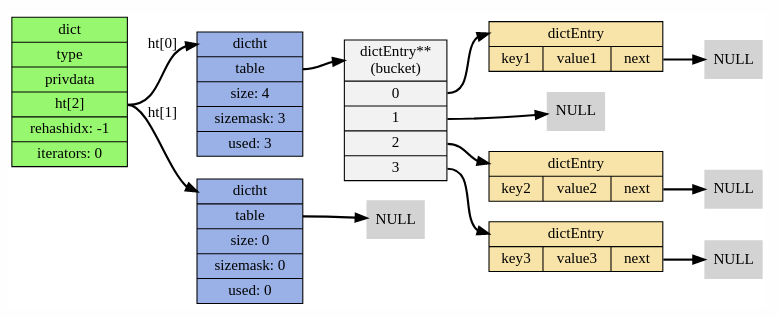
|
||||
|
||||
<br>
|
||||
|
|
@ -39,6 +37,7 @@ Overall, the memory needed during the spike is $32N + 16N=48N$ bytes.
|
|||
To summarize, RD requires between **16-32 bytes overhead**.
|
||||
|
||||
## Dash table
|
||||
|
||||
[Dashtable](https://arxiv.org/abs/2003.07302) is an evolution of an algorithm from 1979 called [extendible hashing](https://en.wikipedia.org/wiki/Extendible_hashing).
|
||||
|
||||
Similarly to a classic hashtable, dashtable (DT) also holds an array of pointers at front. However, unlike with classic tables, it points to `segments` and not to linked lists of items. Each `segment` is, in fact, a mini-hashtable of constant size. The front array of pointers to segments is called `directory`. Similarly to a classic table, when an item is inserted into a DT, it first determines the destination segment based on item's hashvalue. The segment is implemented as a hashtable with open-addressed hashing scheme and as I said - constant in size. Once segment is determined, the item inserted into one of its buckets. If an item was successfully inserted, we finished, otherwise, the segment is "full" and needs splitting. The DT splits the contents of a full segment in two segments, and the additional segment is added to the directory. Then it tries to reinsert the item again. To summarize, the classic chaining hash-table is built upon a dynamic array of linked-lists while dashtable is more like a dynamic array of flat hash-tables of constant size.
|
||||
|
|
@ -63,6 +62,7 @@ adds it to the directory and the items from the old segment partly moved to the
|
|||
|
||||
Now we can explain why seemingly similar data-structure has an advantage over a classic hashtable
|
||||
in terms of memory and cpu.
|
||||
|
||||
1. Memory: we need `~N/840` entries or `8N/840` bytes in dashtable directory to host N items on average.
|
||||
Basically, the overhead of directory almost disappears in DT. Say for 1M items we will
|
||||
need ~1200 segments or 9600 bytes for the main array. That's in contrast to RD where
|
||||
|
|
@ -97,13 +97,13 @@ overall memory usage. Its primary goal is to reduce waste around dictionary mana
|
|||
Having said that, by reducing metadata waste we could insert dragonfly-specific attributes
|
||||
into a table's metadata in order to implement other intelligent algorithms like forkless save. This is where some the Dragonfly's disrupting qualities [can be seen](#forkless-save).
|
||||
|
||||
|
||||
## Benchmarks
|
||||
|
||||
There are many other improvements in dragonfly that save memory besides DT. I will not be
|
||||
able to cover them all here. The results below show the final result as of May 2022.
|
||||
|
||||
### Populate single-threaded
|
||||
|
||||
To compare RD vs DT I often use an internal debugging command "debug populate" that quickly fills both datastores with data. It just saves time and gives more consistent results compared to memtier_benchmark.
|
||||
It also shows the raw speed at which each dictionary gets filled without intermediary factors like networking, parsing etc.
|
||||
I deliberately fill datasets with a small data to show how overhead of metadata differs between two data structures.
|
||||
|
|
@ -138,6 +138,7 @@ single-threaded case ,depends where we stand compared to hash table utilization)
|
|||
This example shows how much memory Dragonfly uses during BGSAVE under load compared to Redis. Btw, BGSAVE and SAVE in Dragonfly is the same procedure because it's implemented using fully asynchronous algorithm that maintains point-in-time snapshot guarantees.
|
||||
|
||||
This test consists of 3 steps:
|
||||
|
||||
1. Execute `debug populate 5000000 key 1024` command on both servers to quickly fill them up
|
||||
with ~5GB of data.
|
||||
2. Run `memtier_benchmark --ratio 1:0 -n 600000 --threads=2 -c 20 --distinct-client-seed --key-prefix="key:" --hide-histogram --key-maximum=5000000 -d 1024` command in order to send constant update traffic. This traffic should not affect substantially the memory usage of both servers.
|
||||
|
|
@ -151,11 +152,12 @@ As you can see on the graph, Redis uses 50% more memory even before BGSAVE start
|
|||
where Redis finishes its snapshot, reaching almost x3 times more memory usage at peak.
|
||||
|
||||
### Expiry of items during writes
|
||||
|
||||
Efficient Expiry is very important for many scenarios. See, for example,
|
||||
[Pelikan paper'21](https://twitter.github.io/pelikan/2021/segcache.html). Twitter team says
|
||||
that their their memory footprint could be reduced by as much as by 60% by employing better expiry methodology. The authors of the post above show pros and cons of expiration methods in the table below:
|
||||
|
||||
<img src="https://twitter.github.io/pelikan/assets/img/segcache/expiration.svg" width="400">
|
||||
<img src="https://pelikan.io/assets/img/segcache/expiration.svg" width="400">
|
||||
|
||||
They argue that proactive expiration is very important for timely deletion of expired items.
|
||||
Dragonfly, employs its own intelligent garbage collection procedure. By leveraging DashTable
|
||||
|
|
@ -190,7 +192,6 @@ So for `30%` bigger working set Dragonfly needed `25%` less memory at peak.
|
|||
<em>*Please ignore the performance advantage of Dragonfly over Redis in this test - it has no meaning.
|
||||
I run it locally on my machine and ot does not represent a real throughput benchmark. </em>
|
||||
|
||||
|
||||
<br>
|
||||
|
||||
*All diagrams in this doc are created in [drawio app](https://app.diagrams.net/).*
|
||||
|
|
|
|||
Loading…
Add table
Add a link
Reference in a new issue